I started in computer security on BBS networks in the 1980s. Today I teach AP Computer Science and Cybersecurity while building toward a full-time remote role in SOC analysis or penetration testing.
My TryHackMe profile sits at USA Rank #76, Top 1% globally. I hold a Physical Penetration Testing certification, am completing Security+ on the CompTIA track, and document every room I complete in this blog.
I also run MakerMindStudio, a 3D printing and laser engraving operation, and publish health and systems writing under the FACTOTUM Protocol.
TryHackMe room writeups published as completed. Each walkthrough covers the tools used, the logic behind each step, and the security concepts the room demonstrates.
Code review for security vulnerabilities with a written findings report, severity ratings, and specific fixes. Three tiers: Entry Scan ($499), Standard Audit ($1,200–$2,500), and Full Certification. Entry Scan turnaround is 72 hours.
I review your resume and LinkedIn profile against current cybersecurity and tech hiring standards. You get a marked-up document with specific rewrites, not a checklist of generic suggestions.
A structured 90-day plan built around your current certifications, experience level, and target role. Covers what to study, what to build, and what to skip.
Line-by-line feedback on AP Computer Science Free Response Questions. Written for students preparing for the exam or teachers who want a second set of eyes on student work.
Frontier Models Are Overkill for Most Production Workloads
Topics: AI Models, Open Source, Ollama, Production AI, Infrastructure
The trading bot running on my Jetson Orin Nano uses llama3.2:3b for its daily summary task. Not because it was the first model I tried. deepseek-r1:14b at 9GB does not fit the 7.4GB unified memory pool. llama3.1:8b mostly fits and crashes at the edge. llama3.2:3b stays stable at roughly 2GB and writes the summary well.
The model writes one paragraph per day: what position the bot holds, what the P&L is, what the trailing stop did. It does that task well. The fact that it is several capability tiers below GPT-5.5 does not show up anywhere in the output.
...
The Ethical AI Company Billed You for Using Competitor Tools
Topics: Anthropic, Claude Code, AI Ethics, Billing, Vendor Trust
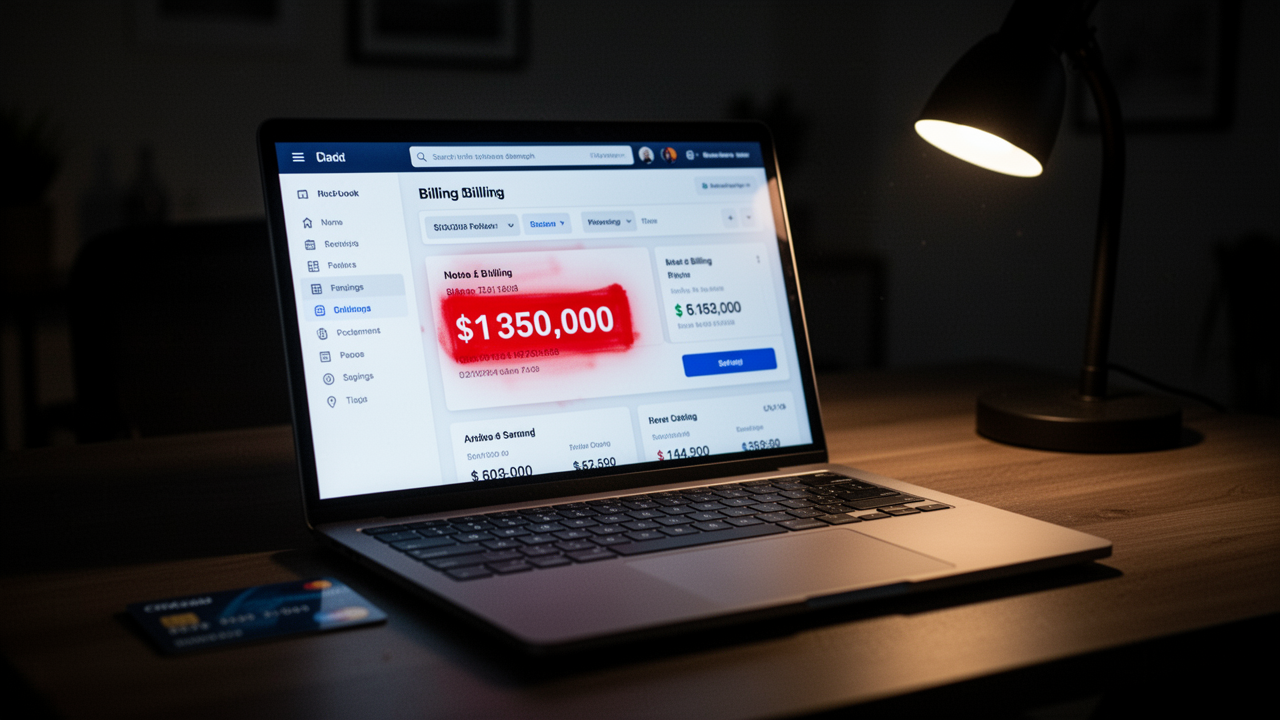
Anthropic’s detection logic found “hermes.md” in a user’s git commit history. The user was on the $200/month Claude Max plan with 86% of their usage allocation untouched and no active session running. Anthropic billed $200.98 in extra charges. When the user reported it, support acknowledged the billing error three times and refused the refund.
The post reached 1.4 million views. Anthropic then issued the refund plus one month of credit.
...
Claude Code on DeepSeek: 17x Cheaper
Topics: Claude Code, DeepSeek, AI Costs, Developer Tools, Open Source
Claude Code’s tool ecosystem and the model it runs on are two separate things. A project called DeepClaude treats them that way.
DeepClaude intercepts API calls from Claude Code and routes them to DeepSeek V4 instead of Anthropic’s models. The tool layer, file editing, bash execution, session context, autonomous loops, stays intact. The inference backend changes. The cost difference is approximately 17x.
...
AI Outperformed ER Doctors in a Harvard Trial
Topics: AI, Healthcare, Clinical Trials, Emergency Medicine
Listen to this article
Harvard ran a controlled trial of AI performance in emergency triage and published the results this week. The AI outperformed emergency physicians on diagnostic accuracy.
Most of the conversations that follow a result like this focus immediately on liability. That conversation is worth having. It is not the most important one.
What Emergency Triage Actually Tests Emergency triage is decision-making under a specific set of conditions: incomplete information, time pressure, high consequence, and compounding cognitive load from case volume. A physician who has seen 40 patients in a shift is making probabilistic judgments under fatigue in a way that a physician at the start of a shift is not.
...
The 47 Percent Debugging Skill Drop
Topics: AI Coding Agents, Developer Skills, Claude Code, Software Engineering
Anthropic published research this year showing that developers who leaned heavily on AI coding agents experienced a 47% drop in debugging skills. The finding that made it uncomfortable is in the same document: supervising an AI coding agent effectively requires the exact debugging skills that atrophy from using one.
You need the skill to catch what the agent gets wrong. Using the agent is what costs you the skill.
...
DeepSeek V4 Broke the Pricing Argument
Topics: AI Models, Open Source, Enterprise Costs, API Pricing
Claude Opus 4.7 costs $5 per million input tokens and $25 per million output tokens. GPT-5.5 is $5 input and $30 output. DeepSeek V4, released as open weights on Friday, costs $1.74 input and $3.48 output, runs a 1 million token context window, and scores within a few benchmark points of both on math and Q&A.
The pricing argument for closed frontier models just got harder to make.
...
I Built a Trading Bot That Runs Its LLM on a Jetson in My Closet
Topics: Python, Alpaca, Ollama, Jetson Orin Nano, Trading Automation
The trading bot watches XNDU every five minutes during market hours. XNDU is a photonic quantum computing company. Photonics means room temperature operation. The cooling infrastructure that makes quantum computing prohibitively expensive at scale is not part of the design. XNDU had solid financials this week and got upgraded to a strong buy. I queued 100 paper shares for the 9:31 AM open on April 30, 10% trailing stop, $5,000 position cap.
...
CVE-2026-31431: The Optimization That Opened Root
A 732-byte Python script dropped today gives any unprivileged user a root shell on every mainstream Linux distribution running a kernel built after 2017. No race condition. No kernel-specific offsets. A straight logic flaw in code that has been shipping on your servers, your CI/CD runners, and your cloud instances for eight years.
The vulnerability is CVE-2026-31431. The researchers named it Copy Fail.
Here is what happened.
The AF_ALG Interface In 2003, the Linux kernel crypto API grew a socket interface: AF_ALG. The idea was sound — expose kernel crypto primitives to userland without requiring applications to link against third-party crypto libraries. You open an AF_ALG socket, set the algorithm, feed it data, get results back. Clean separation between userland and kernel.
...
I Built AI Software in 2009. Here Is What ASU's New Learning Platform Gets Wrong.
In 2009, I created the math algorithm for VIPRE and VASIS. The work used K-nearest neighbor pattern recognition applied to audio samples, trained to classify stress signatures with enough precision for production use. Nobody gave me a syllabus for that. My team and I built it by reading papers, writing code, testing against real data, and keeping a failure log that was longer than the documentation.
That was seventeen years before Arizona State University launched a platform called Atomic.
...
I Built a 25-Minute Timer That Forces You to Name What You're Actually Doing
Razor is a work session timer with one requirement before the clock starts: declare the specific task and which project it belongs to. Type API_Caller: WeatherApp and the 25 minutes begin. When time is up, it asks whether you finished. The completed list grows. That is it.
I built it because I stood in my house one afternoon and counted ten unfinished projects in the same room.
Not ten across the whole house. Ten in that room. A workbench with three tools out, a shelf half-painted, a cabinet with one door rehung and one still leaning against the wall. I kept starting the next thing before the last thing was done. The thing before that too. And the thing before that.
...